NeurIPS 2025 Accepted Papers Overview
NeurIPS (Annual Conference on Neural Information Processing Systems) is a top-tier conference in machine learning, alongside ICML and ICLR, recognized as one of the most challenging, highest-level, and most influential conferences in the field! NeurIPS is a CCF Class A conference and Core Conference Ranking Class A conference, with an H5 index of 278! Founded in 1987 in Canada by neural network scholars from the connectionist school, NeurIPS has grown in influence, with paper topics primarily focused on machine learning, artificial intelligence, and statistics.
The Large Model Center at Nanjing University’s School of Computer Science has 9 papers accepted to NeurIPS 2025.
01
Title: Gated Integration of Low-Rank Adaptation for Continual Learning of Large Language Models
Authors: Yan-Shuo Liang, Jia-Rui Chen, Wu-Jun Li
Institution: Nanjing University
Abstract:
Thanks to the rich knowledge obtained from large-scale pre-training and subsequent fine-tuning strategies, existing large language models (LLMs) have demonstrated excellent performance across a wide range of tasks. However, when LLMs learn multiple downstream tasks sequentially, they often forget previously learned knowledge, leading to significant performance degradation on old tasks—a phenomenon known as catastrophic forgetting. Catastrophic forgetting hinders LLMs from continuously accumulating new knowledge, making it crucial to design continual learning methods that can overcome this challenge. Meanwhile, Low-Rank Adaptation (LoRA), as one of the most representative methods in parameter-efficient fine-tuning, has gained widespread attention in continual learning for LLMs. LoRA reparameterizes pre-trained weights into low-rank forms, requiring only a small number of parameters to be updated for task adaptation. Compared to full parameter updates, LoRA significantly improves fine-tuning efficiency. However, existing LoRA-based continual learning methods still have limitations. They typically expand new LoRA branches when learning new tasks while freezing old branches, thereby avoiding forgetting caused by directly modifying old parameters. During inference, these methods usually adopt simple addition to integrate new and old branches. This approach forces new and old branches to contribute equally to old tasks, which may instead cause new branches to significantly interfere with old tasks, exacerbating forgetting and reducing overall performance. To address this, we propose GainLoRA (gated integration of low-rank adaptation), a new continual learning method for LLMs. GainLoRA expands new LoRA branches for each new task and dynamically integrates new and old branches through a gating module. By imposing initialization and update constraints on the new gating module, GainLoRA significantly reduces interference from new LoRA branches on old tasks, effectively mitigating forgetting and improving the overall performance of LLMs in continual learning.
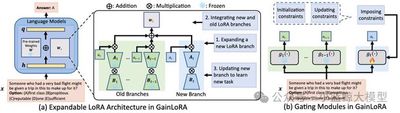
Figure 1
02
Title: StreamForest: Efficient Online Video Understanding with Persistent Event Memory
Authors: Xiangyu Zeng, Kefan Qiu, Qingyu Zhang, Xinhao Li, Jing Wang, Jiaxin Li, Ziang Yan, Kun Tian, Meng Tian, Xinhai Zhao, Yi Wang, Limin Wang
Institution: Nanjing University, Shanghai AI Laboratory, Zhejiang University, Huawei Noah’s Ark Lab, Yinwang Intelligent Technology
Abstract:
Multimodal large language models have made significant progress in video understanding in recent years. However, due to historical visual feature storage limitations and insufficient real-time spatiotemporal reasoning capabilities, their effectiveness in real-time streaming scenarios remains limited. To address these challenges, we propose StreamForest, a novel architecture specifically designed for streaming video understanding. The core of StreamForest is the Persistent Event Memory Forest, a memory mechanism that can adaptively organize video frames into multiple event-level tree structures. This process is guided by a penalty function based on temporal distance, content similarity, and merging frequency, enabling efficient long-term memory retention under limited computational resources. To enhance real-time perception, we introduce the Fine-grained Spatiotemporal Window, which captures detailed short-term visual cues to improve current scene perception. Additionally, we propose OnlineIT, an instruction tuning dataset customized for streaming video tasks. OnlineIT significantly improves MLLM performance in real-time perception and future prediction. To evaluate its generalization ability in practical applications, we introduce ODV-Bench, a new benchmark focused on real-time streaming video understanding in autonomous driving scenarios. Experimental results show that StreamForest achieves state-of-the-art performance, reaching 77.3% accuracy on StreamingBench, 60.5% on OVBench, and 55.6% on OVO-Bench. Notably, even under extreme visual token compression (limited to 1024 tokens), the model maintains 96.8% average accuracy across eight benchmarks (relative to the default 8k setting). These results highlight StreamForest’s robustness, efficiency, and versatility in streaming video understanding.
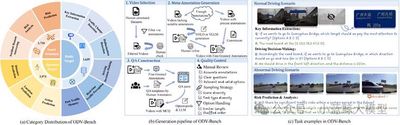
Figure 2
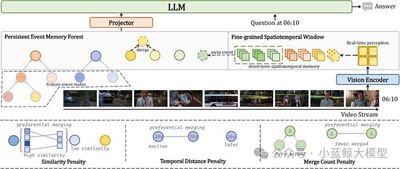
Figure 3
03
Title: LongVPO: From Anchored Cues to Self-Reasoning for Long-Form Video Preference Optimization
Authors: Zhenpeng Huang, Jiaqi Li, Zihan Jia, Xinhao Li, Desen Meng, Lingxue Song, Xi Chen, Liang Li, Limin Wang
Institution: Nanjing University, China Mobile Research Institute
Abstract:
Current vision-language models (VLMs) have limited performance in long video understanding: they rely on expensive and scarce long video annotations, and short-context models easily overlook intermediate content when extended to long sequences, causing performance imbalance between long and short tasks. To address this, we propose LongVPO—a two-stage direct preference optimization framework that requires no long video annotations. LongVPO first uses “anchored cues” to automatically synthesize preference data from short video clips, then achieves cross-clip alignment through “self-reasoning” on real long videos, learning complex long-range reasoning capabilities. Using only 16K synthetic data, LongVPO achieves superior performance on LVBench, LongVideoBench, MLVU, VideoMME, and other benchmarks while maintaining strong performance on short video tasks, providing a new paradigm for efficient and scalable long video understanding.
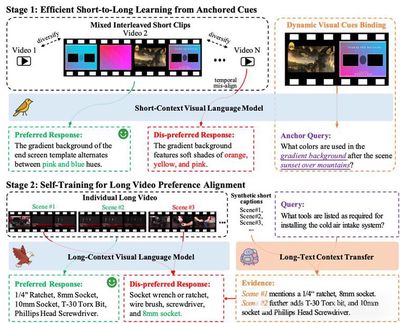
Figure 4
04
Title: Eagle 2.5: Boosting Long-Context Post-Training for Frontier Vision-Language Models
Authors: Guo Chen, Zhiqi Li, Shihao Wang, Jindong Jiang, Yicheng Liu, Lidong Lu, De-An Huang, Wonmin Byeon, Matthieu Le, Tuomas Rintamaki, Tyler Poon, Max Ehrlich, Tong Lu, Limin Wang, Bryan Catanzaro, Jan Kautz, Andrew Tao, Zhiding Yu, Guilin Liu
Institution: Nanjing University, NVIDIA, Hong Kong Polytechnic University, Rutgers University
Abstract:
Eagle 2.5 is a series of frontier vision-language models (VLMs) designed for long-context multimodal understanding. Existing VLMs mainly focus on short-context tasks, with insufficient support for long video understanding and high-resolution image processing. Eagle 2.5 proposes a general training framework with two core technologies: Automatic Degradation Sampling (ADS) and Image Area Preservation (IAP), which dynamically allocate visual and text input budgets and maintain image integrity when segmenting. Additionally, the authors introduce a progressive mixed post-training strategy that gradually extends context length to improve model stability in handling diverse inputs. To support training, they construct the new Eagle-Video-110K dataset, providing story-level and clip-level dual annotations to enhance long video understanding capabilities. Experiments show that Eagle 2.5 achieves significant improvements on multiple long video and image understanding benchmarks. For example, the 8B parameter Eagle 2.5 achieves 72.4% on Video-MME with 512 frame input, approaching the performance of larger models like GPT-4o and Qwen2.5-VL-72B. The model also performs excellently on high-resolution image understanding tasks. In summary, Eagle 2.5 achieves efficient and powerful long-context multimodal understanding capabilities through innovative sampling strategies, progressive training methods, and large-scale multi-level datasets, providing a strong direction for future high-performance VLM development.
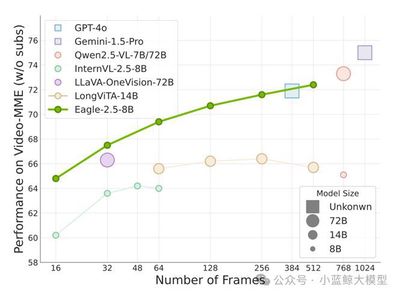
Figure 5
05
Title: VideoChat-R1.5: Visual Test-Time Scaling to Reinforce Multimodal Reasoning by Iterative Perception
Authors: Ziang Yan, Xinhao Li, Yinan He, Zhengrong Yue, Xiangyu Zeng, Yali Wang, Yu Qiao, Limin Wang, Yi Wang
Institution: Zhejiang University, Shanghai AI Laboratory, Nanjing University, Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences
Abstract:
Infusing reasoning capabilities into multimodal large language models is key to achieving human-level perception and understanding. Existing methods mostly rely on the reasoning capabilities of LLMs to analyze parsed visual information, but are often limited by static perception stages. This paper proposes “Visual Test-Time Scaling,” which enhances multimodal LLM reasoning capabilities through iterative perception during inference. Under the guidance of updated text predictions, it gradually refines attention to high-confidence spatiotemporal regions, mimicking human hierarchical attention mechanisms. The training process combines reinforcement learning with spatiotemporal supervision signals for end-to-end optimization of reasoning paths. These designs allow multimodal LLMs to improve performance by increasing perception computational capacity. Extensive experiments validate the effectiveness and generalization of the iterative perception method across various tasks and benchmarks. The newly introduced Videochat-R1.5 model achieves significant improvements across more than 15 benchmarks covering video dialogue, video reasoning, and spatiotemporal perception, with an average improvement of more than 5% compared to robust baselines like Qwen2.5VL-3B and -7B.
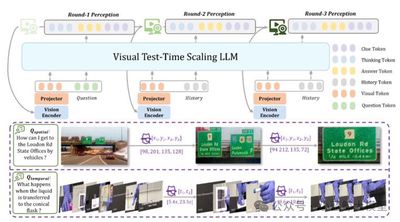
Figure 6
06
Title: MotionRAG: Motion Retrieval-Augmented Image-to-Video Generation
Authors: Chenhui Zhu, Yilu Wu, Shuai Wang, Gangshan Wu, Limin Wang
Institution: Nanjing University
Abstract:
Thanks to the development of diffusion models, image-to-video generation technology has made significant progress. However, generating motion-realistic videos remains a formidable challenge. The core of this challenge lies in accurately modeling the complexity of motion, which requires capturing physical laws, object interactions, and domain-specific motion patterns—prior knowledge that is difficult to generalize effectively across diverse scenarios. To address this, we propose MotionRAG, a retrieval-augmented generation framework. This framework extracts and transfers motion priors from relevant reference videos through a Context-Aware Motion Adaptation (CAMA) mechanism to improve the motion realism of generated videos. The core technical innovations include: (1) Retrieval-based motion representation extraction: using video encoders and resamplers to extract semantic-level motion features from retrieved reference videos; (2) Context learning-based motion adaptation method: efficiently learning and transferring motion patterns from multiple retrieved reference videos to target scenarios through a causal Transformer architecture; (3) Attention motion injection adapter: injecting motion features into pre-trained video diffusion models to enhance motion realism. Extensive experiments demonstrate that our method achieves significant improvements across multiple scenarios and various base models, introducing only negligible computational overhead during inference. Furthermore, its modular design supports zero-shot generalization to new domains—simply updating the retrieval database without retraining any model components. This research enhances the core capabilities of video generation systems by enabling efficient retrieval and transfer of motion priors, providing a new paradigm for synthesizing videos with realistic dynamic effects.
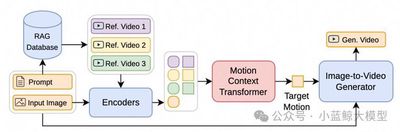
Figure 7
07
Title: Loquetier: A Virtualized Multi-LoRA Framework for Unified LLM Fine-tuning and Serving
Authors: Yuchen Zhang, Hanyue Du, Chun Cao, Jingwei Xu
Institution: Nanjing University
Abstract:
Low-Rank Adaptation (LoRA) has become a widely adopted parameter-efficient fine-tuning (PEFT) technique for adapting large language models (LLMs) to downstream tasks. Although numerous studies have explored strategies for unifying LLM training and serving, the domain of unified fine-tuning and inference for LoRA-based models remains underexplored. This paper proposes Loquetier—a virtualized multi-LoRA framework that seamlessly integrates LoRA fine-tuning and inference serving in a single runtime environment. Loquetier consists of two main components: (1) a virtualization module that isolates PEFT-based model modifications and supports deploying multiple adapters on a shared single base model; (2) an optimized computational flow with kernel designs that fuse fine-tuning and inference paths in forward propagation, enabling efficient batch processing and minimizing kernel call overhead. In extensive experiments across three task scenarios, Loquetier significantly outperforms existing baselines in both performance and flexibility: achieving 3.0× throughput of top co-serving systems in inference-only tasks, and 46.4× higher service level objective attainment rate than PEFT in unified fine-tuning and inference tasks.
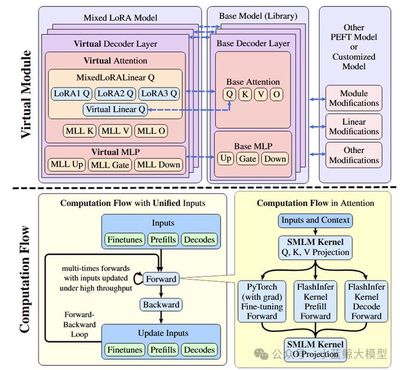
Figure 8
08
Title: 3D Interaction Geometric Pre-training for Molecular Relational Learning
Authors: Namkyeong Lee, Yunhak Oh, Heewoong Noh, Gyoung S. Na, Minkai Xu, Hanchen Wang, Tianfan Fu, Chanyoung Park
Institution: KAIST, KRICT, Stanford University, Genentech, Nanjing University
Abstract:
Accurate prediction of molecular interactions is crucial in drug discovery and materials science. However, existing molecular relational learning methods are mostly limited to using 2D topological structures of molecules, ignoring 3D spatial geometric information that determines the nature of interactions—primarily because obtaining precise 3D interaction conformations is extremely expensive. To break through this bottleneck, we propose 3DMRL, an innovative 3D geometric pre-training framework. The core of this framework is that instead of relying on expensive computations to obtain true interaction conformations, it simulates how molecules contact each other in 3D space by constructing a “virtual interaction environment”—arranging multiple small molecules around a large molecule through random sampling, translation, and rotation. Based on this, we design dual pre-training tasks to guide 2D models to learn 3D geometric information in this virtual environment: one uses contrastive learning to help models understand the global geometric structure of interactions; the other uses an equivariant network to predict fine local relative geometric relationships between molecules, capturing atomic-level interaction details. Extensive experiments show that 3DMRL can significantly improve the performance of various mainstream models on molecular interaction prediction and drug-drug interaction prediction tasks, achieving up to 24.93% performance improvement across 40 tasks and demonstrating excellent generalization capabilities in out-of-distribution scenarios. This work systematically introduces 3D geometric pre-training to the field of molecular relational learning for the first time, laying a solid foundation for developing more accurate and versatile AI-assisted scientific discovery tools.
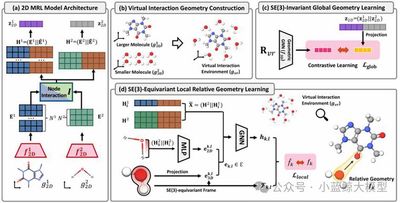
Figure 9
09
Title: EgoExoBench: A Benchmark for First- and Third-person View Video Understanding in MLLMs
Authors: Yuping He, Yifei Huang, Guo Chen, Baoqi Pei, Jilan Xu, Tong Lu, Jiangmiao Pang
Institution: Nanjing University, Shanghai AI Laboratory, University of Tokyo, Zhejiang University, Fudan University
Abstract:
Human intelligence can naturally transfer and integrate knowledge between first-person (egocentric) and third-person (exocentric) perspectives, which is crucial for learning and communication. However, although current multimodal large language models (MLLMs) have achieved significant progress in single-perspective video understanding, they still lack systematic evaluation of cross-perspective reasoning. To address this, we propose EgoExoBench—the first benchmark for evaluating MLLMs’ first-person and third-person video understanding and reasoning capabilities.
EgoExoBench is built on public datasets and contains 7300+ multiple-choice questions (MCQs) covering 11 sub-tasks, divided into three major challenges: semantic alignment, viewpoint association, and temporal reasoning. Task designs cover matching from task, action, object, to person levels, as well as cross-perspective spatial correspondence and event sequence reasoning.
The research team conducted systematic evaluation of 13 mainstream open-source and closed-source MLLMs (such as GPT-4o, Claude 3.7 Sonnet, Qwen2.5-VL, InternVL3, etc.). Results show that these models perform well on single-perspective tasks but exhibit significant performance degradation on cross-perspective tasks. For example, the best open-source model Qwen2.5-VL-72B achieves only 47% overall accuracy, while humans achieve over 90% accuracy on the same tasks. Further experiments show that chain-of-thought (CoT) prompting does not improve performance and even reduces accuracy on some tasks, indicating that cross-perspective reasoning remains a major challenge for existing models.
In summary, EgoExoBench provides a systematic and scalable evaluation framework that helps advance embodied agents and human-robot collaboration systems with human-like cross-perspective intelligence.

Figure 10